CMU 15-445/645 (fall 2023) Project 3 QUERY EXECUTION
本篇为15-445 project 3 query execution的总结。
相较于Project 1和2 Buffer Pool和Index较为底层的组件,Project 3主要关注的是图中红框的部分,从这里开始我们能够从一个比较高的角度来理解BusTub是如何运行的,也感谢迟先生在23Spring为BusTub引入了一整套Query Processing层,让我们可以在本地实际运行SQL,帮助我们更直观的理解一条SQL在数据库里的执行流程。红框中各组件负责的功能如下:
- Parser:根据sql语句生成一颗抽象语法树(学过编译原理的同学应该熟悉,这就是编译器的前端,BusTub直接采用了
pg_query库将SQL语句parse成抽象语法树)。 - Binder:结合数据库的元信息,将抽象语法树中的标识符绑定到BusTub能理解的实体(C++类)上,转成一个具有库表信息的语义语法树。
- Planner:根据语义语法树生成逻辑执行计划树,也叫查询计划。
- Optimizer:根据某些优化规则,重写优化后的查询计划(BusTub是rule-based优化器,意味着优化都要根据我们自己写的规则来,目前业界采用的优化器也有cost-based, data-dependent-based等等)。
- Executors:根据查询计划,生成具体的算子执行树。
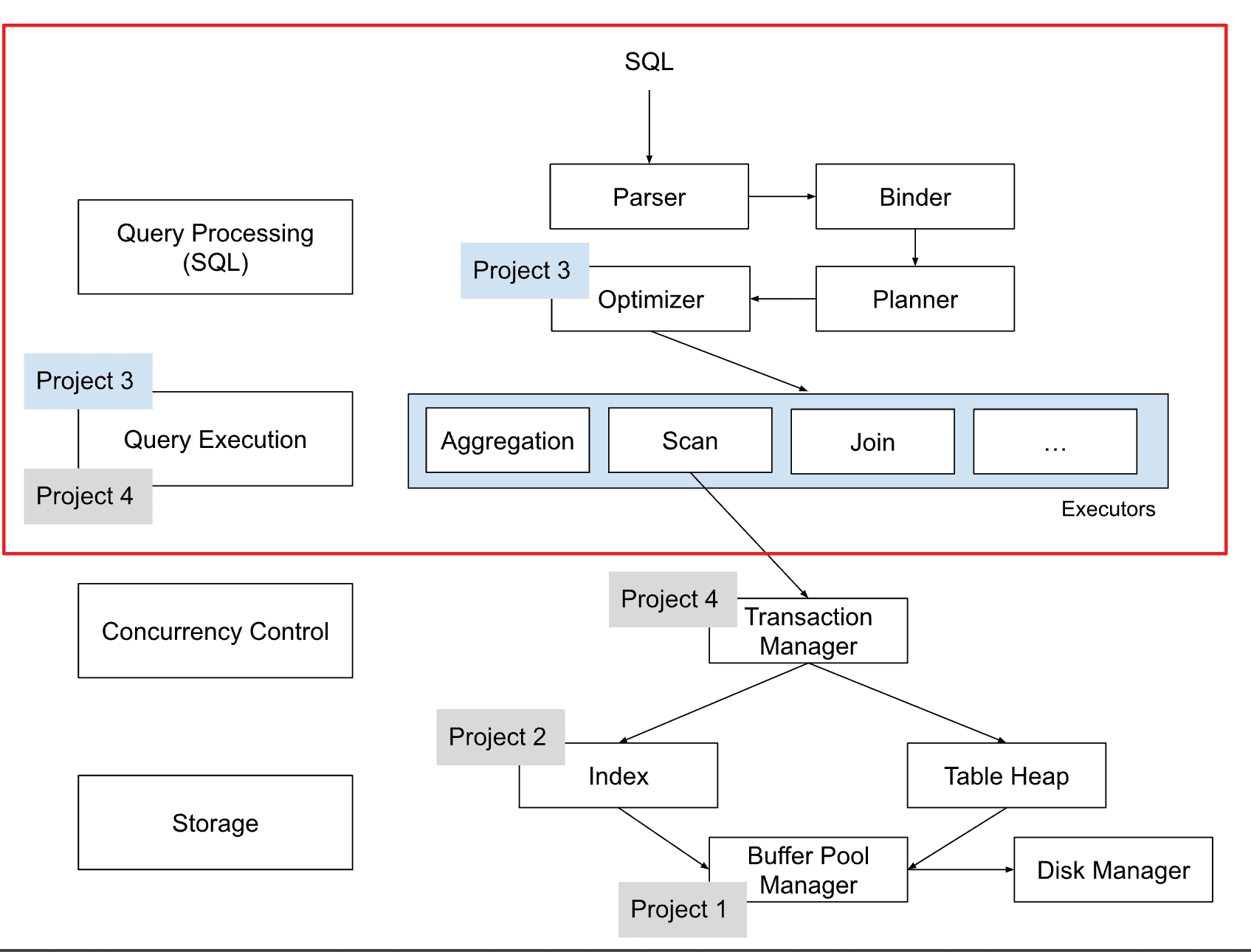
这篇文章给BusTub的查询流程和结构画了比较详细的图,可以参考一下。
在Clion中Debug(观察)BusTub
通过编译运行tools/shell.cpp,我们可以直接在Clion里通过命令行输入SQL进行调试,记得在Debug configurations里加上参数--disable-tty。
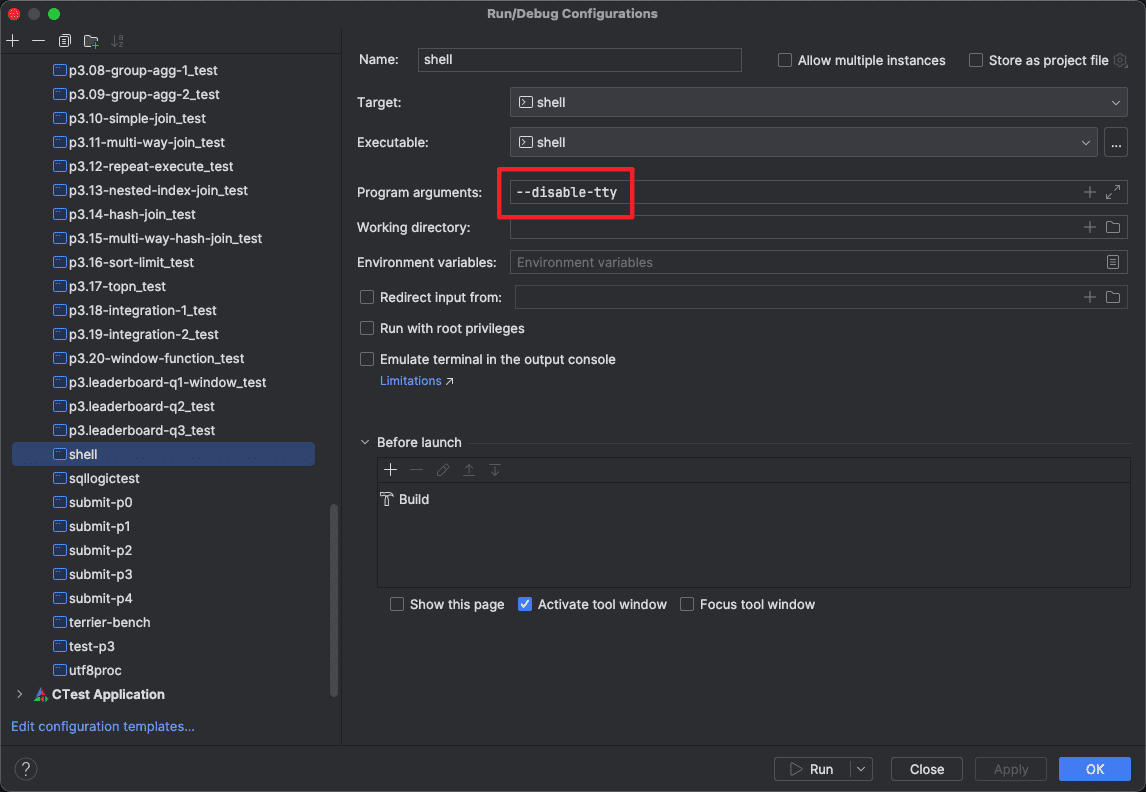
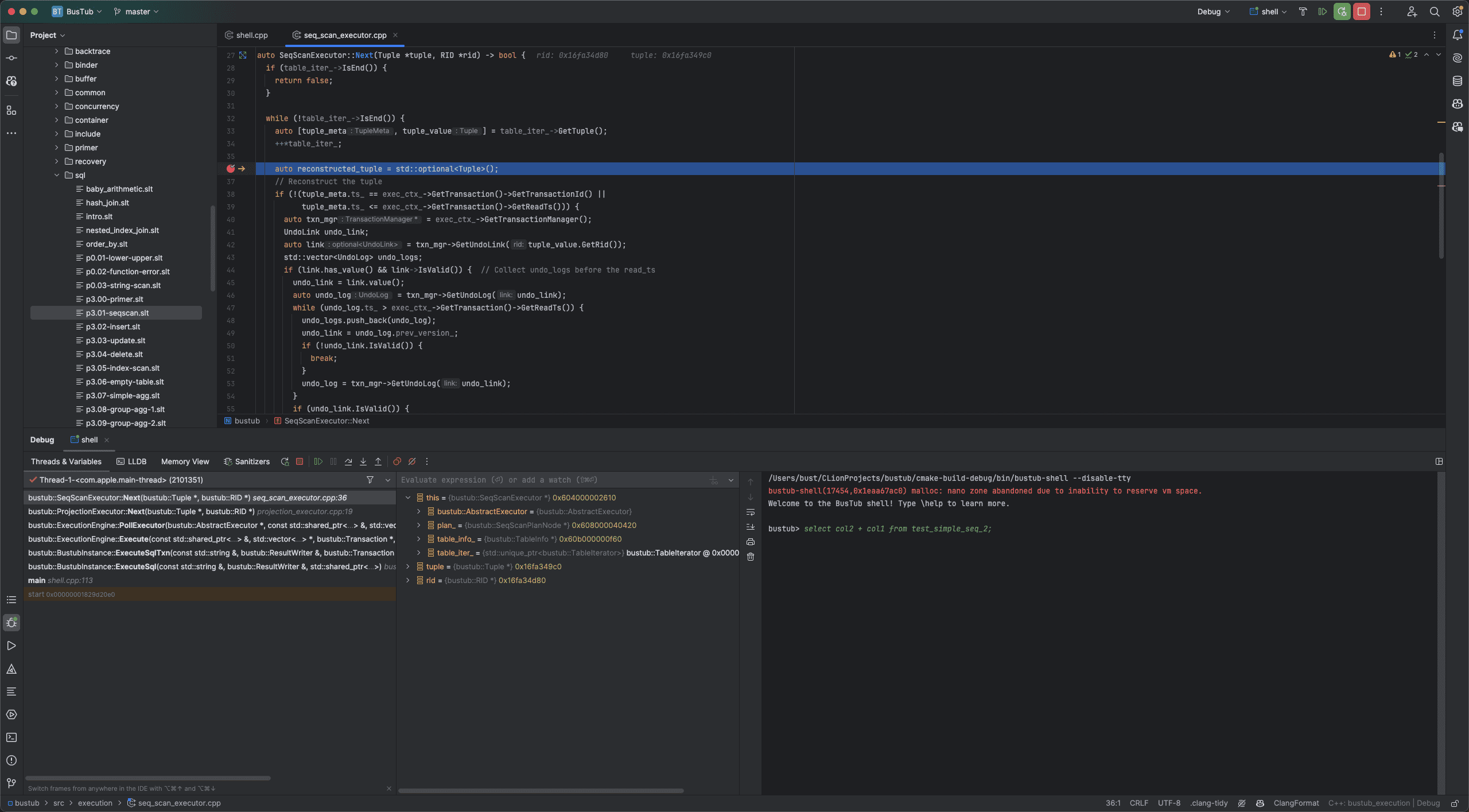
这样我们就能通过打断点观察SQL的运行流程了,这里以一条seqscan语句为例,我先在seq_scan_executor里打了断点,然后以Debug模式运行shell,并在命令行里输入select col2 + col1 from test_simple_seq_2;这条会触发seqscan的SQL语句,执行后我们可以在下方很清晰的看到函数的调用栈,各个变量的值,对于调试来说十分的直观。
同时在输入的SQL语句前加上EXPLAIN命令,BusTub会将生成执行计划的过程全部打印出来,这对我们调试优化器会很有帮助:
1 | |
火山模型
BusTub采用了解释计算模型,将关系代数中每一种操作抽象为一个 Operator,将整个 SQL 构建成一个 Operator 树,从根节点到叶子结点自上而下地递归调用 next() 函数。优点就是每个算子我们都可以独立实现,不必过多考虑其他算子的特性,缺点就是每次算子计算只会返回一个tuple,这会造成大量的函数调用开销。对于火山模型的优化方向有编译执行和向量化,具体可以参考这篇文章。
算子实现
算子中增删改查都比较简单,实现一个其他稍微改一改就可以,需要注意的是executor 本身并不保存查询计划的信息,应该通过 executor 的成员 plan 来得知该如何进行本次计算,例如 SeqScanExecutor 需要向 SeqScanPlanNode 询问自己该扫描哪张表。所有要用到的系统资源,例如 Catalog,Buffer Pool 等,都由 ExecutorContext 提供。这里比较麻烦的一点是我不知道输出的tuple schema长啥样,经过调试发现输出结果的schema是在src/execution/plan_node.cpp定义的,参考这里对结果进行拼装就可以了。
Aggregation Executor
BusTub简化了aggregation算子,我们可以认为所有结果都可以放进内存,意味着不需要实现一个可持久化的hash table,使用std::unordered_map就可以满足需求。
Aggregation算子是pipeline breaker,意味着 Aggregation 的 Init() 函数中,我们就要将所有结果全部计算出来而不是调用一次next去计算一次聚合结果。举个例子,比如下面这条 sql:
1 | |
结果的每条 tuple 都是一个 t.x 的聚合,而要得到同一个 t.x 对应的 max(t.y),必须要遍历整张表。因此,Aggregation 需要在 Init() 中直接计算出全部结果,将结果暂存,再在 Next() 中一条一条地 emit。中间结果则保存在SimpleAggregationHashTable中。
Aggregation中间结果计算流程如下:
- 在
Init()中调用子算子,并将子算子输出的tuple生成对应的kv对调用InsertCombine()插入SimpleAggregationHashTable中。Key为代表group by字段的数组,Value为aggregate的值的数组。 - 判断是否是第一次插入该group by字段,是则调用
GenerateInitialAggregateValue()为其生成初值,这里注意CountStarAggregate这一AggregationType初值为0,其他初值都为NULL。 - 更新aggregate的值,根据对应聚合操作符进行相应的更新,例如
CountStarAggregate就直接对旧值+1,MaxAggregate就应该比较新值与旧值大小进行替换。
中间结果计算出来以后Next()就比较简单了,直接用SimpleAggregationHashTable的iterator依次输出结果就行。
NestedLoopJoin Executor, HashJoin Executor, Optimizer
理论上join操作细节会比较多,但是因为测试用例比较简单,我偷懒直接在Init()阶段把左右表都存到vector里,Next()阶段时直接比较两个vector里的值🤣,记得调一下右子算子的Init就能骗过测试(别学我hh)。同时记得保留每次left_iter,right_iter和当前left_tuple是否匹配到right_tuple的信息,可以保证不会漏结果或者left outer join时没匹配到值输出空值。
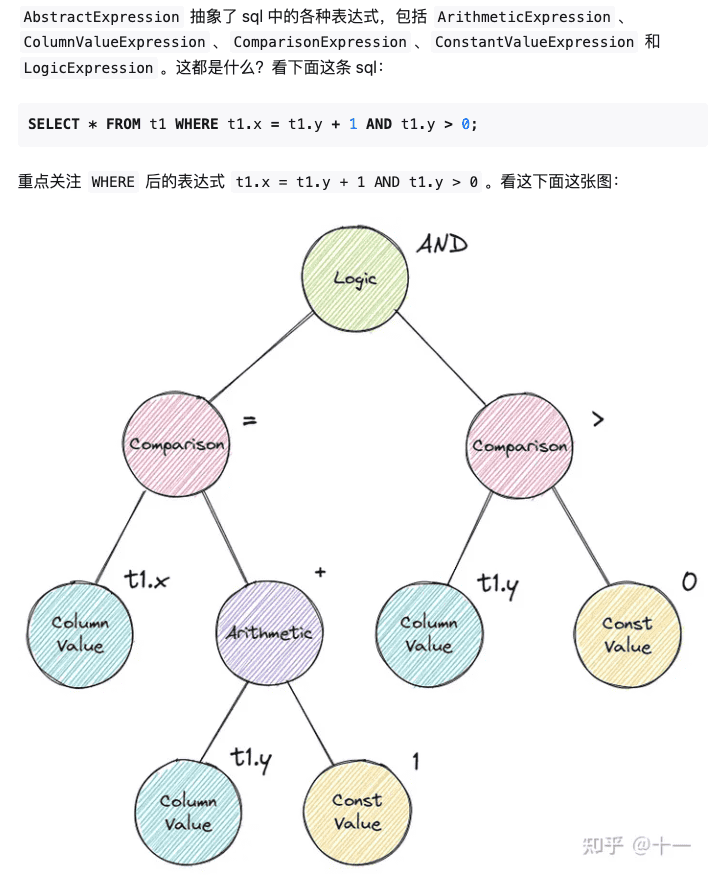
HashJoin也比较简单,参考Aggregation算子生成key的函数作为unordered_map的key值即可。将NLJ优化成HashJoin的优化规则是唯一一次我在BusTub编写中用到比较复杂的算法,我们需要判断是否所有条件表达式是否都是相等条件同时还需要将左右两边的join key给分离开。但表达式是一个树形结构,这里看图会清楚一些(图源见水印),我们不能直接进行简单的判断。这里我直接对树进行递归将所有表达式给取出来,合法的表达式只能有ComparisonExpression, LogicExpression, ColumnValueExpression,且所有叶节点都应该是ColumnValueExpression,一旦有其他类型的表达式则不能优化成Hash Join,同时对所有ColumnValueExpression调用GetTupleIdx()方法,如果值为0就是左join key,否则就是右join key。
Sort, Limit, Top-n Executor
这三个算子比较简单,sort可以学习一下现代C++的lambda函数该怎么写,Top-n我直接偷懒用priority_queue解决了,最优的方法应该是手写一个固定大小的优先队列。(C++ 17std::partial_sort方法好像也可以实现,感兴趣的同学可以自己研究一下)
Window Function Executor
最恶心的一个算子,算是aggregation的加强版,对着测试用例慢慢调就行了,反正我写的时候挺崩溃的。
总结
做完Project 3再回头看迟先生的这篇文章,真的会感受到BusTub设计的巧妙。Project 3如此大的工作量也让我断了去CMU的念想,北美小衡水不是吹的(不过CMU也没录我😇)。
这周学习了一下cmake,对着bustub的CMakeList看了半天算是大概了解了一个大型的C++项目是怎么构建的。在学习的同时也在感叹自己基础知识的缺失,从小都是用着IDE的一键编译,从来没有自己了解过一个程序从编译到链接执行是怎么进行的,看其他的C++开源项目跟看天书一样,连环境都不知道怎么配置,读硕士的时候一定要把这些缺失的知识都补回来。